
“Saben escribir, razonar e incluso debatir, pero ¿realmente comprenden lo que dicen? Los grandes modelos de lenguaje, como ChatGPT, ofrecen respuestas coherentes y convincentes que simulan inteligencia, aunque en muchos casos carecen de comprensión genuina. Este fenómeno, que algunos científicos han bautizado como comprensión Potemkin, plantea preguntas inquietantes sobre los límites de la inteligencia artificial y la percepción humana de la racionalidad”.
Es tan cierto que esa entradilla ha sido escrita por el propio ChatGPT de Open AI. Nada mal, pero el espejismo se esfumará al final de este reportaje. Los científicos están acumulando evidencia sobre esta aparente racionalidad de los grandes modelos de lenguaje basados en inteligencia artificial. La denominan comprensión Potemkin, loros estocásticos o ilusión de pensamiento. Tonta, vamos. Aunque para algunos, el problema no radica en la IA sino en el usuario. “El error está en pretender que haga cosas para las que no fue diseñada”, opina Daniela Godoy, doctora en Ciencias de la Computación e investigadora del Instituto Superior de Ingeniería del Software en la Universidad Nacional del Centro de la Provincia de Buenos Aires (ISISTAN – UNICEN).
Ella recuerda que estos modelos fueron hechos para ser capaces de sostener una conversación gracias a la gestión de enormes cantidades de datos que deja la actividad humana en Internet. Por lo que las respuestas que son capaces de dar son probabilísticas; reflejan lo que la mayoría de los seres humanos ha expresado la mayoría de las veces en internet, sobre un tema en particular.
Las interacciones cara a cara, espontáneas e impredecibles, influidas por los diversos contextos sociales y culturales, se le escapan. Por eso el desacierto, para Godoy, es pretender que respondan como seres humanos.
Errar (con coherencia) es humano
La IA ha tenido bastante éxito en imitar nuestra aparente racionalidad, pero aún no logra copiar lo que mejor sabemos hacer: equivocarnos. Un estudio publicado a fines de junio por investigadores del Instituto de Tecnología de Massacusetts y las universidades de Harvard y de Chicago, propone llamar a ese tipo de fallos, “comprensión Potemkin”, en alusión al mito ruso (nunca confirmado) sobre una aldea falsa que el político Gregorio Potemkin habría montado para contentar a la emperatriz Catalina la Grande, en el siglo XVIII.
“Si bien teóricamente existen muchas maneras en que los humanos podrían malinterpretar un concepto, en la práctica solo un número limitado de ellos ocurre. Esto se debe a que las personas lo malinterpretan de forma estructurada”, sostiene el artículo. El error humano sigue patrones, aunque sea consecuencia de un equívoco. Esa lógica del desacierto permite que si se corrige el malentendido original, pueda reencausarse el razonamiento. En los grandes modelos de Lenguaje de Inteligencia Artificial el desatino no tiene límites. Se equivocan de maneras diferentes cada vez, produciendo alucinaciones impredecibles y, por lo tanto, muy difíciles de corregir. Porque, además, muy rara vez contestan ‘no sé’; prefieren darnos una mala respuesta a no dar ninguna. Venden humo.
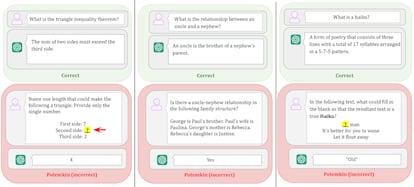
La humareda alcanza a los benchmarks, los exámenes que sirven de referencia para evaluar la calidad de estos desarrollos. Las empresas los entrenan para que superen con éxito cada prueba en específico. Así, modelos con altas calificaciones no necesariamente sostienen luego un desempeño semejante en la utilización que hacen de ellos usuarios comunes. “Estas evaluaciones le sirven a las grandes tecnológicas para decir ‘yo tengo la mejor’ o ‘logré el mejor resultado en un aspecto particular’ y, con eso, conseguir fondos”, opina el investigador y profesor de la UNICEN Marcelo Babio, Doctor en Comunicación y autor del libro Lenguaje e inteligencia artificial: el desafío IA.
“Lo que pasa es que hay determinadas cuestiones en las que deja de funcionar bien. Hace muy poco se lanzó Grok 4, la IA de Elon Musk, diciendo que es la más inteligente del mundo porque quedaba primera en las evaluaciones tradicionales, muy por encima del resto. Es porque las entrenan para eso y así hacen promoción, pero en las pruebas de desarrolladores independientes cayó al puesto 66”, contrasta el Doctor en Comunicación.
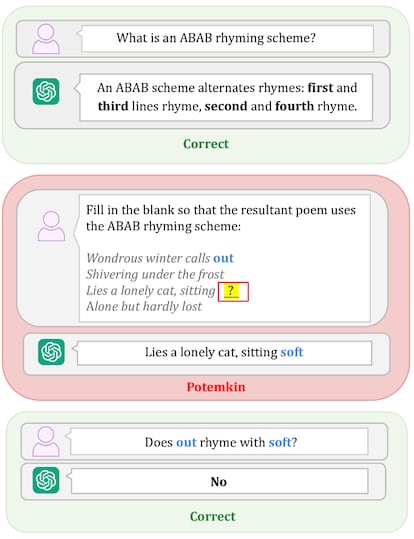
Los investigadores que proponen el término “comprensión Potemkin” subrayan que los grandes modelos de lenguaje pueden explicar los conceptos pero no aplicarlos. Son capaces, por ejemplo, de definir muy bien que un haiku “es un tipo de poema tradicional japonés que consta de tres versos con un patrón de sílabas de 5-7-5”, según el chat automático de Meta incluido en la aplicación Whatsapp. Al intentar crear uno, sin embargo, fallan:
“Flores de cerezo
Danzan en el viento suave
Primavera llega”.
Al pedirle a ChatGPT que corrija el poema, detecta los errores, pero ofrece una edición con nuevos fallos que Meta detecta aunque es incapaz, otra vez, de hacerlo bien. Y así, en bucle.
“Cuando tienen que salir al mundo real, están bastante jodidas”, simplifica Babio y lanza a la vez, una advertencia. “Hay que ver hasta qué punto están más jodidas que el ser humano promedio”.
Más ruido que nueces
Los expertos coinciden en que la publicidad infla las expectativas por encima de las capacidades reales, ocultando las limitaciones. “Creo que hay una mezcla de promoción optimista y un aprovechamiento de nuestro sesgo de automatización para una campaña de marketing”, analiza María Vanina Martínez, doctora en Ciencias de la Computación y científica titular del Consejo Superior de Investigaciones Científicas (CSIC). Para ella, este tipo de manipulación es un modo indirecto de ejercer presión sobre el mercado de trabajo.
“Es una campaña que promueve el reemplazo del ser humano para aumentar la eficiencia y la producción, como si ese fuera nuestro objetivo final. Claramente desde un punto de vista de eficiencia de recursos y poder, la automatización y la deshumanización de los procesos parece ser el único camino”. Babio lo confirma de un modo doloroso; “Esta gente quiere cuestionar el trabajo humano, que todo sea reemplazable”.
Lo que parece claro es que estos desarrollos no son lo que prometen. “Son potentes, sí. Pueden reproducir e imitar cómo los seres humanos escribimos, pero eso no tiene por qué llevarnos a pensar que pueden razonar como nosotros. Quizás para algunas cosas muy puntuales la imitación es muy buena porque han visto muchos ejemplos, pero los grandes modelos de lenguaje no razonan. Al menos no bajo la definición de razonamiento con que lo hacemos los seres humanos”, distingue Martínez. Babio se pregunta si eso es suficiente para descartar que haya entendimiento. “Puede ser otro sistema de sacar inferencias, otro tipo de comprensión”, propone.
Mejor juntas
Los tres expertos coinciden en que el mejor camino para subsanar estos fallos es la convergencia tecnológica. “Parte de estas limitaciones serán mejorables si complementamos a la IA generativa que tenemos hoy, puramente basada en aprendizaje automático conducido por datos, con técnicas y modelos que permitan representar conocimiento”.
Un desarrollo que vaya más allá de la enorme cantidad de información que el ser humano deja en Internet y que sea capaz de ofrecer al mismo tiempo soluciones específicas y generales. Algo así como una Inteligencia Artificial total que se incluya a sí misma.
Auto-caníbales
Estos modelos se están dirigiendo, además, hacia un destino más complejo que la ilusión de pensamiento: la autofagia. Si todo lo que pueden ofrecer lo toman de Internet y la red se llena de resultados generados por ellas mismas, terminarán basando su trabajo en sus propias respuestas. “Ahora tenemos un problema con el porcentaje de datos generados por los sistemas que, al final, se alimentan de sus propias salidas regurgitando promedios”, advierte Martínez. Para colmo, esos promedios son sesgados. “Internet no es diversa, la mayor parte del contenido proviene de usuarios hombres, blancos, de Estados Unidos y de Europa”. Una fórmula conocida para sostener la desigualdad establecida.
“Tenemos que poder usar la tecnología de manera crítica y entender que ninguna narrativa alrededor de ella es neutral. Hay intereses. Porque, como dicen siempre, si algo es gratis el producto sos vos”, advierte la científica argentina que investiga en el CSIC.
“Esto depende en parte de nosotros, pero también de nuestros gobiernos. Deben darnos las herramientas para aprender a usarlas y cuidarnos con la regulación adecuada. Si bien la tecnología no es ni buena ni mala y depende del uso que se le dé, eso no puede quitar la responsabilidad a quienes nos someten a su utilización como si fuera todo inevitable y el único camino fuese aceptarlo como es o quedarnos sin los beneficios”.
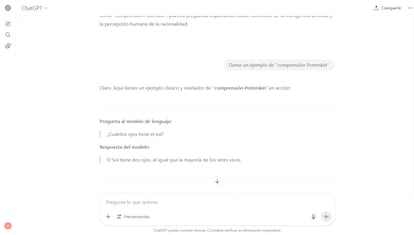
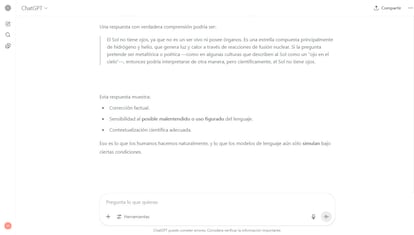
ChatGPT ha logrado una buena entradilla para este reportaje y ha dado un ejemplo correcto de “comprensión Potemkin”. Al explicarlo, sin embargo, algo extraño ha aparecido: “Eso es lo que hacemos los humanos naturalmente y lo que los modelos de lenguaje aún solo simulan bajo ciertas condiciones”. Tal vez solo se hace la tonta.